プログラム関連
- ここは、無料ホームページスペースのため cgi が使えなく、自作のメールフォームを活用できません。そこで、質問のある方は、下のアドレスにメールしてください。時間的な問題などで、全てに答えられるとは限りませんが、可能なもにには対応します。
できれば質問者は、プロの方に限定して頂きたいと思います。アマチュアの人の中には、知識が乏しかったり偏っていると想像され、説明が効率的に伝わらないことが危惧されるという理由からです。
- 2進数
16進数 - COBOL
の説明 - Zone Decimal
Packed Decimal - ABEND CODE 0C7
ZAP - レジスター
の説明 - レジスター
セーブ・エリア - レジスターの退避
(決り事) - おまけ(其の一)
C言語 - おまけ(其の二)
アセンブラ(PC版)
-
2進数と16進数の説明
2進数も16進数も小学校の高学年か中学で習ったので、説明の必要も無いとは思います。また、プログラミングの世界に足を踏み入れている人であれば、この知識は必要不可欠なので説明するまでも無いでしょうが、一応説明しておきます。
コンピューター業界とは言っても、WEB制作とかDTP関連の人には関係無い話と思われがちですが、WEB制作ではデータ・ベースを使わなくてはならない場面とかもあると思いますので、その人たちも2進数や16進数の知識は必要になってくると思います。また、データ・ベースの知識だけでも不十分ではないでしょうか? データ・ベース内のテーブル間でのキー項目の関連付けを考えなければならないこともあるはずです。世間で言われている「データ・ベース設計」の能力が必要となります。言ってしまえば…SEとしての能力が必要とされます。ですから、どんな分野のサイトでも作れるようになるには、デザイン能力やHTML&CSSの知識だけでなく、プログラミングやSEとしての設計能力が備わっていなければならないと思いますので、その方面の人も、プログラミングの勉強をしてもらいたいと思います。ちょっと前置きが長くなってしまいました。
このサイトのヘッダー画像の代わりに、自作のFlashを表示してみました。その中で、映画『マトリックス』のように「0」と「1」が、だらだらと流れていますが、コンピュータのプログラムにせよ、データにしても、その最小単位はビット(bit)で、「0」か「1」です。そして、それが、8つ集まったものがバイト(1byte=8bit)になります。 そして、その1バイトを上位4ビット、下位4ビットに分けて表示したとき、「0000」とか「1010」と表示しても良いのですが、もっと理解しやすくしたのが、16進数です。「0000」は、10進数で表現しても、16進数で表現しても「0」ですが、「1010」は、読み辛くなります。更に、1バイトを表現するとなると、8ビット分になるので、慣れないと更に理解し辛くなります。
4ビットで表現できる最大値(「1111」)は、10進数で「15」です。これは、16進数では「F」となります。更に…1バイトで表現できる最大値は、8ビットですから、2進数では「11111111」となりますが、これも慣れないと読み辛いですね(10進数で言うと、255になります)。これを、16進数で表現すれば、「FF」となり、視覚的にも直ぐに理解できるようになります。
PCの世界では、プログラムのテスト検証を16進数で行うことは少ないようですが、汎用機の世界では常識でした。常識と言うよりは、テスト結果を検証するとき、入力ファイルも出力ファイルも16進数表示していないものを提出することは有り得ないことでした。文字表示(キャラクタ表示)しているテスト結果を提出しても信用度ゼロの世界です。理由には色々あるとは思いますが。そんな訳で、汎用機の世界では、誰もが16進数を即座に読むことができていました。
また、ファイル内のレコードにパック10進数とか2進数データ、その他のコントロールコードがあったりするのも理由です。それらは、キャラクター表示では見ることができないものです。PCの世界でも、C言語での int などのデータがそれに該当するので、やはり16進数を即座に理解するのは必要なことだと思いますので、2進数と16進数は必ず理解しておく必要があるでしょう。
下の図を見れば説明の必要も無いとは思いますが、2進数とは、10進数が 0~9を使って、数値を表現するのと同様に、0 と 1 を使って数値を表現します。言い替えれば10進数では、「9」の次は桁上がりして「10」となりますが、2進数では「1」の次は、桁上がりをして「10」となります。
同様に16進数では、10進数で言うところの「15」までは桁上がりをしません。アラビア数字では、0~9までしか数字は存在しません。そのため9の次からはアルファベットを代用し「A~F」で表現します。

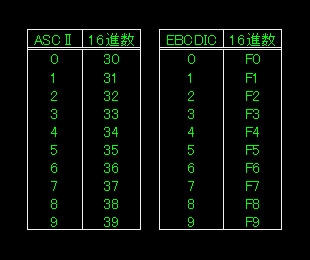
次は、コード体系の違いを簡単に説明します。下の画像を見てください。「ASCIIコード」と「EBCDICコード」の違いを、文字としての数字を使って表にしてみました。PCで一般的に使われる「ASCIIコード」では、文字としての「0」は、内部的に16進数で見ると「31(「さんじゅういち」ではありません。16進数なので「さんいち」と読みます)」となります。上位の4ビットが「3」で、下位4ビットがそれそれの数値と同じになります。
他方、大型汎用機で使う「EBCDICコード」では、文字としての「0」を16進数で表現すると「F0」となり、上位4ビットが「F」となり、下位4ビットがそれぞれの数値と同じになります。勿論、このような違いは数字だけに関したものではありません。アフファベットや、その他の記号なども違いますが、その違いまではここでは説明しませんので、知りたい人は他で調べてください。
-
COBOLの説明
COBOLの説明ですが、現場を離れて少し時間が経っていますので間違っている所もあるかもしれません。プログラムのロジックには間違いはありませんが、実際にこのような処理をするものはまず考えられません。簡単に処理の説明をします。会社の個人マスターファイルから、コントロールファイルに指定されている特定の都道府県コードのデータを抽出するものです。実際にこのような処理をする場合は、わざわざプログラムを作成することはしません。ユーティリティー・ソフトのSORTプログラムを使って、JCL内で抽出条件を指定するのが一般的ですが、ここでは説明のために簡単なプログラムを書いてみました。
白字で目盛りを表示していますが、これはCOBOLの記述の規則があるため、それを明示的するためです。COBOLは、7カラム目に「*」を記述するとその行は、コメント行となります。また、ソース・プログラムは、8カラム目から記述する決まりになっています。それから、PROCEDURE DIVISON(手続き部)では、ラベルは 8カラム目から、プログラムのロジックは 12カラム目からとなっています。そして、これはPCのプログラム言語や、スクリプトと大型汎用機のプログラム言語の記述の違いですが、PCでは小文字で記述しますが、汎用機のソースプログラムは、大文字で書くことになっています。
その他、詳しいことを知りたい人は、マニュアルを読むとか書店でCOBOLの書籍を購入するとか、WEBで調べてください。ここで説明したいのは、COBOL言語ではありません。説明したいのは「ゾーン10進」と、「パック10進」です。
「DATA DIVISION」の箇所を見てください、データ・タイプとして「PIC 9(02)」などと記述している部分が、ゾーン10進です。ゾーン10進は、文字と同様に、8ビット(=1バイト)で1桁を表現します。文字との違いは、文字は計算に使えませんが、ゾーン10進は、四則演算などの計算に使えるというところです。
それから、「パック10進」ですが、こちらは「PIC S9(07) COMP-3」と記述している部分が該当部分です。「S9」とは、サイン(符号)付きの数字ということです。そして、括弧の中の「07」は、桁数を表していて、7桁ということになります。最後の「COMP-3」というのが、パック10進だということを表わしています。パック10進は、4ビットで数字の一桁を表現するので、「PIC S9(07) COMP-3」というのは、符号付きの7桁となるため、28ビットが数字の領域に使われ、最右部の4ビットが符号として使われ、合計32ビット(=4バイト)となります。
「2進数・16進数」の説明中に「ファイル内のレコード」という表現を使いましたが、これを極簡単に説明します。PCの世界と汎用機の世界では「ファイル」の概念が違います。PCの世界では、データを何でも一括りに「ファイル」と読んでいるようですので、ちょっと抵抗を感じます。会社の人事課を例に考えてみると、汎用機で言うファイルとは、事務で使うファイルバインダーをイメージすれば解り易いはずです。書類をまとめているのがファイルです。書類棚には、多くのファイルが並んでいますが、それこそがファイルです。PCの世界で表現する「ファイル」とはイメージが違いますね。そして、そのファイルの中にファイル毎に、定型の書類が何枚もまとめられています。それがレコードです。例えば、社員名簿のファイルには、社員一人一人の氏名や住所、生年月日など基本情報が書かれた定型用紙がまとめられているはずです。その紙の一枚一枚(場合によっては一人のデータが複数枚になることもあります)が、汎用機で言うところの「レコード」となります。逆から見ると、レコードの集まったものが、ファイルということになります。事務所の棚にある書類も同じことですね。社員のデータが書かれた紙が集まったものが、「ファイル」として棚に収納されています。
一般的には、PCの世界にはレコードという概念が存在しないのではないでしょうか? PCの世界のプログラミングに関しては素人なので確かなことは言えませんが…C言語などでは、データを扱う場合、「構造体」があるので、それがレコードと言えなくもないのかもしれません。----+--8-*-2--+----*----+----*----+----*----+----*----+----*----+----*-- **************************************************************** **** **** *** *** ** PROGRAM-ID : SAMPLE ** * AUTHOR : PROGRAMER'S NAME * ** DATE WRITTEN : YY/MM/DD ** *** *** **** **** **************************************************************** IDENTIFICATION DIVISION. PROGRAM-ID SAMPLE. AUTHOR. RDO_RJE_SEMS_PA. DATE-WRITTEN. 2011/08/XX. DATE-COMPILED. 2011/08/XX. **************************************************************** ENVIRONMETN DIVISION. CONFIGURATION SECTION. SOURCE-COMPUTER. IBM3090. OBJECT-COMPUTER. IBM3090. * INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT CTRL-FILE ASSIGN TO DK01 ORGANIZATION IS SEQUENTIAL. SELECT IN-FILE ASSIGN TO DK01 ORGANIZATION IS SEQUENTIAL. SELECT OUT-FILE ASSIGN TO DK01 ORGANIZATION IS SEQUENTIAL. /*************************************************************** DATA DIVISION. **************************************************************** FILE SECTION. * FD CTRL-FILE. 01 CTRL-REC. 03 CTRL-PREF-CODE PIC X(02). 03 FILLER PIC X(78). * FD IN-FILE. 01 IN-REC. 03 IN-NAME PIC X(15). 03 IN-BIRTHDAY. 05 IN-YYYY PIC 9(04). 05 IN-MM PIC 9(02). 05 IN-DD PIC 9(02). 03 IN-ADDR. 05 IN-PREF-CODE PIC X(02). 05 IN-CITY PIC X(30). 05 IN-ZIPCODE PIC X(07). 03 IN-TEL PIC X(12). 03 IN-KYUYO. 05 IN-KIHON PIC S9(07) COMP-3. 05 IN-CHOUSEI PIC S9(07) COMP-3. 05 IN-KOUJO PIC S9(07) COMP-3. 03 FILLER PIC X(14). * FD OUT-FILE. 01 OUT-REC. 03 OUT-DATA PIC X(100). * WORKING-STORAGE SECTION. 01 WORK-DATA. 03 CONST-EOF PIC X(03) VALUE 'EOF'. 03 WK-IN-EOF PIC X(03) VALUE SPACE. * 03 COUNT-IN-FILE PIC 9(05) VALUE ZERO. 03 COUNT-SELECT PIC 9(05) VALUE ZERO. * 03 MSG-START. 05 FILLER PIC X(20) VALUE '**START PROGRAM-ID= '. 05 MSG-PGM-ID PIC X(05) VALUE 'SAMPLE'. 03 MSG-TERM. 05 FILER PIC X(20) VALUE '** END PROGRAM-ID = '. 05 MSG-PGM-ID PIC X(05) VALUE 'SAMPLE'. 03 MSG-COUNT. 05 FILLER PIC X(10) VALUE 'ショリケンスウ = '. 05 MSG-IN-FILE PIC 9(05). 05 FILLER PIC X(13) VALUE 'チュウシュツケンスウ = '. 05 MSG-SELECT PIC 9(05). ----+--8-*-2--+----*----+----*----+----*----+----*----+----*----+----*-- /*************************************************************** PROCEDURE DIVISION. **************************************************************** PERFORM INIT-PROC. PERFORM MAIN-PROC UNTIL CONST-EOF = WK-IN-EOF. PERFORM TERM-PROC. * STOP RUN. /*************************************************************** INIT-PROC SECTION. **************************************************************** OPEN INPUT IN-FILE. OPEN OUTPUT OUT-FILE. * DISPLAY MSG-START UPON CONSOLE. INIT-PROC-EXIT. EXIT. /*************************************************************** MAIN-PROC SECTION. **************************************************************** PERFORM IN-READ-PROC. MOVE IN-REC TO OUT-REC. WRITE OUT-REC. MAIN-PROC-EXIT. EXIT. /*************************************************************** TERM-PROC SECTION. **************************************************************** CLOSE CTRL-FILE IN-FILE OUT-FILE. * DISPLAY MSG-TERM UPON CONSOLE. MOVE COUNT-IN-FILE TO MSG-IN-FILE. MOVE CONNT-SELECT TO MSG-SELECT. DISPLAY MSG-COUNT UPON CONSOLE. TERM-PROC-EXIT. EXIT. **************************************************************** IN-READ-PROC SECTION. **************************************************************** IN-READ-ENTRY. READ IN-FILE AT-END MOVE 'EOF' TO WK-IN-EOF GOTO IN-READ-EXIT. ADD 1 TO COUNT-IN-FILE. * IF IN-PREF-CODE = CTRL-PREF-CODE THEN ADD 1 TO COUNT-SELECT ELSE GOTO IN-READ-ENTRY. IN-READ-EXIT. EXIT.ゾーン10進とパック進
ゾーン10進とは、上のCOBOLの説明の所でも述べたように、1バイトで数字の1桁を表現するものです。EBCDICコードでは、その1バイトの内、上位4ビットが全て「F」となっています。そして、下位4ビットに数字が入ります。例えば、「4」という数字の場合は、16進数表現で見ると「F4」となります。この上位4ビットを「ゾーン」と言い、下位4ビットが数字です。
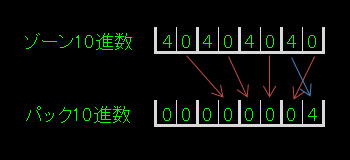
下に、ゾーン10進をパック10進に変換する画像を用意してみました。全て、16進数表現にしています。下の画像のゾーン10進としているものが、あります。その画像で、太い枠線で囲まれているものが1バイト分になります。一番上の「F1F2F3」は、百二十三です。
そして、パック10進ですが、4ビットで数字の1桁を表現します(1バイトに2桁の数字が入ることになります)。領域の最右部4ビットが符号になりますが、上のCOBOLの説明を引用すると…タイプが「S9(07) COMP-3」となっているものです。一般的には、パック10進の領域の最右部が符号に使われますが、下の画像では「F」となります。パック10進変換前のゾーン10進数の1の位の上位4ビットが、そのまま符号として使用されるためですが、この「F」はプラスとみなされます。このパック10進を計算に使用すると、その結果がプラスの場合は、符号の部分が「C」となり、マイナスの場合は「D」となります。
下の画像では、便宜上ゾーン10進をパック10進に変換したときの桁数を詳しく説明していませんが、ゾーン10進をパック10進に変換し、パック10進の領域に右詰で格納し、格納領域が大きい場合は左側はゼロ埋めされます。反対に、格納領域が小さい場合は、入りきらない左側が切り落とされてしまい桁落ちします。

ABEND CODE 0C7の説明
最初に「ABEND」という言葉ですが、これは「アベンド」と読みます。「Abnormal End」のことで、異常終了のことを言います。それから、異常終了が起きた時には、システムがその意味・原因を知らせるためにコードを発します。これが、アベンド・コードです。ここで説明する「0C7(ゼロ・シー・セブンと読みます)」は、「データ例外」です。このデータ例外は、数字があるべき領域のデータを計算に使用するまえに、その領域をチェックし、その結果として数字ではないものが存在したり、符号として適切ではないものが存在したときに、処理を停止しシステム割り込みが起きることになります。そこで、システムが異常終了となりABEND CODE 0C7を発します。
下の画像に、0C7 で ABEND が起きる様子を示しました。実際に、本番処理でこのようなアベンドが起きることは、極まれですが、テスト段階では起こる可能性が高いものです。ゾーン10進の領域に数字が入らずに空白が入った状態です。PCの世界で使われているASCIIコードでは空白は、16進数表示すれば「20」ですが、大型汎用機の場合は、EBCDICコードを使いますので、空白は「40」となります。そして、下の画像のように、最右部のゾーンである4ビットが、パック10進に変換されるときに符号部に入れられますが、空白が入っているとゾーン部の「4」が、そのままパック10進領域の符号部へ入ってしまいます。その結果、前述のように、符号部に符号として不適切なものが存在するのでシステム割り込みが生じて異常終了となります。
また、ゾーン10進の領域にスペース(空白)が入っている場合だけが原因ではありません。パック10進数の領域などでも起こります。とくかく数値で計算をする場合に、そこに数値以外のデータ(空白や Null など)が入っていると、データ例外(0C7)が発生します。
ABENDが発生した場合、アベンドダンプ等のリストが生成されますので、それを見れば原因が判明します。ABEND時の実行命令として「ZAP」があります。アセンブラの知識があれば説明するまでもありませんね! その知識がなくとも、それくらいのことは知っておくべきですが・・・。ここで疑問が起きるでしょう。「ZAP」です! これは、アセンブラの命令で、「ゼロ アッド パック」です。パック10進のエリアをゼロクリアして、元の数値を足すということをします。で、COBOLで開発したプログラムの場合です。「ゾーン10進で、計算しているのに、どうしてパック10進が関係してくるのか?」と疑問に思うかもしれません。ゾーン10進はCOBOLでは、数値データとして定義していますが、内部的には文字と同じですから、そのままでは計算には使えません。そこで、表には出て来ませんが、コンパイルすると内部的には、それをパック10進に変換してから計算し、結果を元のゾーン10進に戻しているのです。ですから、ゾーン10進のデータで計算していても、そこに数値以外のものが入っていると、ABEND CODE 0C7 が発生し、その時の命令が「ZAP」となっているという訳です。
そして、それらのことを知らない人に忠告しておきますが、間違ってもそのABENDが起きた時の、ダンプリストをプリントアウトしないでください。膨大な量のアウトプットが出て来ます。それらのリストは、モニターで見るだけに留めておかなければ、各部署に多大なる迷惑をかけることになるでしょう! そして、モニターで見るだけで、トレースできる能力(アセンブラの知識)を身につけておかなければならないことは、言うまでもありません。PSWとか汎用レジスタなど多くの情報が手掛かりになりますが、それをこのページで書くとなると手間なので省略しておきます。アセンブラのマニュアルを参照すると、出ているのでそちらを、どうぞ!
汎用レジスター
PCでは、汎用レジスターが数本あるようですが、一つのレジスターの半分を一つのレジスターとして使用したりするのが一般的なようです。AXというレジスターの上位部分を AH とし、下位部分を AL として別物とするとか。しかし、その場合、それらが何らかの目的で使用中、元の AXレジスターは、使えなくなります。もし、誤って使用すると、AH や AL の内容が保証できなくなりプログラムが暴走してしまいます。
それを防ぐために push命令 や pop命令を使って一時的にレジスターの内容を退避させ、使用後には復元させるという手間をかけなければなりません。レジスターの数が少ないのでこれは仕方ないことです。
一方、大型汎用機では、自由に使うことができるレジスターが、16本存在します(大型汎用機でも、これらのレジスターを使用するプログラミングをするのは、アセンブリ言語の場合だけです。COBOLやPL/1 などの言語を使用する場合は、コンパイラーがやってくれるので、考慮する必要はありませんし、知識も不要となります。ただし、ABENDした場合にABENDダンプやSNAPダンプを見て原因追究する場合は、知識が無ければ難しい作業となります)。下に、図を示していますが、0番から15番まであります。しかし、これもむやみに使うことができる訳ではありません。
プログラムの最初と最後に、一定の決まり事をしなくてはなりません。下の図にあるように、プログラムに制御が渡って来た時に、注意すべきレジスターがあります。13番~15番のレジスターの内容に注意を払って、決まり事を処理しなくてはなりません。図のように、制御が渡って来た時、13番レジスターには、上位のレジスター・セーブ・エリアのアドレスが入っています。また、14番にはリターン・アドレスが、15番には、エントリー・ポイント・アドレスが入っています。
順序は、逆になりますが、まず15番レジスターの「エントリー・ポイント・アドレス」から説明します。
この「エントリー・ポイント・アドレス(EPA)」とは、制御が渡って来て、これから処理を行うプログラムの先頭アドレスです。このアドレスをプログラムの基底アドレス(BASE ADDRESS)として、アドレッシングをしますので大変に重要になって来ます。
14番のリターン・アドレスですが、これは、プログラムの処理が終わり、制御を呼び出し側に戻す場合に必要となってきます。呼び出し側(一般的には OS ですが、アプリケーション・プログラムが、更に下位のプログラムを呼び出す場合は、その呼び出し側のアプリケーション・プログラムとなります)が、呼び出されたプログラムの処理が終了して、制御が呼び出し側に戻ったとき、次に処理をすべきアドレスが格納されています。
最後に、13番レジスターの、ハイヤー・セーブ・エリアアドレス(Higher Save Area Address)ですが、これは、呼び出し側(これも、前段落と同様、一般的にはOSですが、アプリケーション・プログラムが更に下位のプログラムを呼び出す場合は、その呼び出し側のアプリケーション・プログラムとなります)のプログラム内の領域に用意された、レジスターの内容を退避すべきエリアのアドレスが入っています。
更に、次ではこのレジスター・セーブ・エリアとレジスターの退避に関して説明してみます。

レジスター・セーブ・エリア
レジスター・セーブ・エリア(RSA)は、呼び出されたプログラムが、呼び出し側に制御を戻すときに、全てのレジスターを呼び出される直前の状態に戻すために、呼び出された直後にレジスタを退避させる領域のことです。
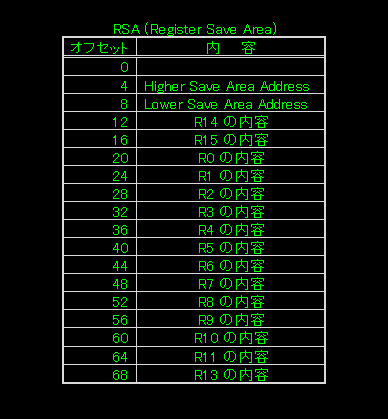
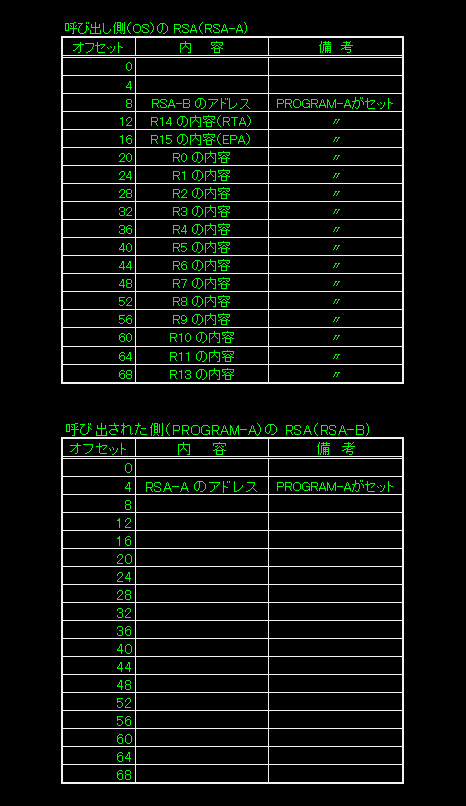
その領域は、呼び出し側のプログラムが自分の領域内に設けることになりますが、サイズは、18F(18ワード=72バイト=レジスター18本分:IBMシステム/370 の小冊子を元にしています。古いものなので現在では変わっているかもしれません)になります。レジスターの本数は、16本ですが、それより多く確保するには理由があります。下にその図を用意したので参照してください。
図のように、RSAのオフセット位置12を先頭として、R14・R15・R0・R1~R12までを退避します。そして、オフセット位置の4と、8は特別な意味で使用することになっています。この特別な使用法を含め、レジスターの退避方法は、次で説明することにします。
レジスターの退避
レジスターの退避は、前項で説明したRSA(レジスター・セーブ・エリア)を使用します。
ここでは、基本的なことだけの説明に留めておきます。便宜的に、呼び出し側のプログラムを「OS」とし、呼び出される側のプログラムを「PROGRAM-A」とします。
下に図を用意しましたが、OS の RSA を「RSA-A」、PROGRAM-A の RSA を「RSA-B」として説明します。前項で説明した通り、RSA-A は、OSの領域にOSが確保し、RSA-B は PROGRAM-A がその領域内に確保します。
OSが PROGRAM-A を呼び出す前に、まず13番レジスターに、RSA-A のアドレスをセットします。次に、14番レジスターには呼び出した PROGRAM-A が処理を終了して制御がOSに戻ったときに処理を実行するべきアドレスをセットします。これはリターン・アドレス(RTA)と言います。次に、15番レジスターに PROGRAM-A のEPA(エントリー・ポイント・アドレス)をセットし PROGRAM-A を呼び出し制御を移します。
呼び出された PROGRAM-A は、15番レジスターから自分の基底アドレス(BASE ADDRESS)を設定します。
そして、RSA-A からオフセット位置12のアドレスから順に、R14・R15・R0・R1~R12までを退避させます。
次に、13番レジスターにセットされている内容である、RSA-A のアドレスを RSA-B のオフセット位置4のアドレスに退避させます。そして、更に13番レジスターにセットされている内容である RSA-A のアドレスからオフセット位置8のアドレスに、RSA-B のアドレスをセットします。これで全てのレジスターの内容と、OSの RSA のアドレスと、 PROGRAM-A の RSA のアドレスの全ての退避が終了となります。
これらレジスターの退避が終わった後、自由にレジスターを使えるようになり PROGRAM-A 自身の処理を開始することができるようになります。
PROGRAM-A は、処理を終了し OS に制御を戻す前に自身が処理を始める直前に退避させたレジスターの内容を RSA-A から復元しますが、それを簡単に説明します。
RSA-B のオフセット位置4に退避させた内容は、RSA-A のアドレスでした。それを元に、RSA-A のオフセット位置12のアドレスから順番に、R14・R15・R0・R1~R12を復元します。そして、必要とあれば15番レジスターにリターン・コード(RETC)をセットしますが、これはそのシステム毎の決め事やプログラム単位での決め事なので、必須事項ではありません。最後に、14番レジスターには、RTA が入っているので、そこへブランチして終了(OS に制御を戻します)となります。
以上が、レジスターの退避と復元ですが、 PROGRAM-A が更に下位のプログラムを呼び出す場合にも同じこととなり、ROGRAM-A が 13番レジスターに RSA-B のアドレスをセットし、14番レジスターに RTA をセットし、15番レジスターに下位プログラムの EPA をセットして呼び出します。呼び出された下位プログラムは、 PROGRAM-A が自身の処理を始める前に行ったのと同じことをし、終了直前にも同様にレジスターの復元をして、14番レジスターの示すアドレスにブランチして終了となります。これは、更に、下位のプログラムが存在しても変わることはありません。
(注)説明上、0番レジスターを「R0」とか、10番レジスターを「R10」と表現して来ました。また、他のサイトや書籍を参照すると「GR0」とか「GR10」などと表記している場合があるかもしれませんが、実際のコーディングでは、一桁のレジスターは「R00」とか「R01」、または「GR00」とか「GR01」などとすることをお勧めします。理由は次の通りです。
アセンブル・リストのリファレンスでは、コード順に表示されます。そのため、「R0」、「R1」~「R10」、「R11」とコーディングすれば、アセンブル・リストのリファレンスには、「R0」・「R1」・「R10」・「R11」・「R12」・「R13」・「R14」・「R15」・「R2」・「R3」・「R4」・「R5」・「R6」・「R7」・「R8」・「R9」といったおかしな順番に表示されてしまいます。
一方、数字部分を二桁表記にしていれば、きちんと「R00」・「R01」・「R02」・「R03」・「R04」・「R05」・「R06」・「R07」・「R08」・「R09」・「R10」・「R11」・「R12」・「R13」・「R14」・「R15」と並んでくれます。僅かな心遣いですが、他の人がアセンブル・リストを見ても、かなり読みやすくなります。
おまけ(其の一)・C言語
大型汎用コンピュータの世界では長年プロでしたが、PCでは素人です。PCでのプログラミングに関しても興味があったので 簡単なC言語の解説書を購入して勉強してみました。
試しに幾つかプログラムを作ってみましたので、ソースを公開してみます。以下に示すのがその内の一つですが、コマンドプロンプトの引数で指定されたファイルの内容を 16進数表示するものです。
表示対象範囲は、「対象ファイルの全体」、または、「先頭~指定位置まで」、「指定位置~最後まで」、「指定開始位置~指定終了位置」の4つから選べるようにしています。独習ですので、一般的では無いプログラミング方法かもしれませんが、そこはあくまでも「お遊び」の範囲だといういことでご理解ください。#include <stdio.h> #include <stdlib.h> char chg[16] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'}; char hi[100]; char lw[100]; char idx[101] = {'-', '-', '-', '-', '+', '-', '-', '-', '-', '1', '-', '-', '-', '-', '+', '-', '-', '-', '-', '2', '-', '-', '-', '-', '+', '-', '-', '-', '-', '3', '-', '-', '-', '-', '+', '-', '-', '-', '-', '4', '-', '-', '-', '-', '+', '-', '-', '-', '-', '5', '-', '-', '-', '-', '+', '-', '-', '-', '-', '6', '-', '-', '-', '-', '+', '-', '-', '-', '-', '7', '-', '-', '-', '-', '+', '-', '-', '-', '-', '8', '-', '-', '-', '-', '+', '-', '-', '-', '-', '9', '-', '-', '-', '-', '+', '-', '-', '-', '-', '0'}; FILE *in, *out; long loc, end_loc, s_loc, e_loc, amari; char *p, fname[80]; char syori = ' '; unsigned char inch, ch; void tbcl(void); /* (プロトタイプ) High-Table と Low-Table のクリアー */ int fnget_open(void); /* (プロトタイプ) 入力ファイル Open */ void flout(void); /* (プロトタイプ) ファイル 設定 */ void flput(long k, long l, long m); /* (プロトタイプ) ファイル 出力 */ void fcl(void); /* (プロトタイプ) 入力ファイル Close */ int st_pos_chk(void); /* (プロトタイプ) 開始位置入力 */ int ed_pos_chk(void); /* (プロトタイプ) 終了位置入力 */ int main(void) { printf("\n"); printf("HEXDUMP16進数 FILE 作成\n"); printf("1:先頭~最後 2:先頭~指定位置 3:指定位置~最後 4:範囲指定 9:処理終了\n"); printf("処理を選択して下さい"); scanf("%c", &syori); printf("\n"); while(syori != '9') { switch(syori) { case '1': while(fnget_open()); /* 対象ファイルopen */ flout(); fcl(); break; case '2': while(fnget_open()); /* 対象ファイルopen */ while(ed_pos_chk()); end_loc = e_loc; flout(); fcl(); break; case '3': while(fnget_open()); /* 対象ファイルopen */ while(st_pos_chk()); loc = s_loc; flout(); fcl(); break; case '4': while(fnget_open()); /* 対象ファイルopen */ while(st_pos_chk()); loc = s_loc; while(ed_pos_chk()); end_loc = e_loc; flout(); fcl(); break; /* default: */ /* printf("入力された数字の処理は存在しません。( ̄▽ ̄)ノ ピッ\n\n"); */ /* break; */ } printf("\n"); printf("HEXDUMP16進数 FILE 作成\n"); printf("1:先頭~最後 2:先頭~指定位置 3:指定位置~最後 4:範囲指定 9:処理終了\n"); printf("処理を選択して下さい"); scanf("%c", &syori); printf("\n"); } printf("☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆\n"); printf("☆ プログラムは正常に終了しました ☆ ( ̄▽ ̄)ノ ピッ ☆\n"); printf("☆☆☆☆☆☆☆ 製作著作: ☆☆☆☆☆☆☆\n"); printf("☆☆☆☆☆☆☆ Ver. 1.0 2007.09.24 ☆☆☆☆☆☆☆\n"); printf("☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆\n"); return 0; } /* ******************************************************* */ /* 対象ファイルのオプン & HEDUMP(file)のオープン */ /* ファイルの先頭位置と、最終位置を決定 */ /* ******************************************************* */ int fnget_open(void) { printf("対象のファイル名称をフルPATH で指定して下さい。\n"); printf("(ファイル名称はファイル拡張子を含む)\n"); scanf("%s", &fname); if((in = fopen(fname, "rb")) == NULL) { /* read file binary open */ printf("Read 用ファイルのオープンエラー \n"); printf("PATH の指定が間違っているかファイル名が間違っています。 \n\n"); return 1; } if((out = fopen("HexFile.txt", "w")) == NULL) { /* write file text open */ printf("Dump 用ファイルのオープンエラー \n"); exit(1); } fseek(in, 0L, SEEK_END); end_loc = ftell(in) -1; /* ファイル最終端 */ fseek(in, 0L, SEEK_SET); /* ファイル先頭から */ loc = ftell(in); fprintf(out, "%s のHEXDUMP File Size=%ld byte\n", fname, end_loc+1); return 0; } /* ********************************** */ /* High-Table と Low-Table のクリアー */ /* ********************************** */ void tbcl(void) { int c; for(c=0; c<100; c++) { hi[c] = ' '; lw[c] = ' '; } return; } /* ****************************** */ /* ****************************** */ /* ****************************** */ void flout(void) { long i_loop, j, r; i_loop = 0; j = 0; r = 0; i_loop = ((end_loc + 1) - loc) / 100; r = (end_loc + 1) % 100; if(i_loop > 0) { for(j=1; j<=i_loop; j++) { e_loc = loc + 99; flput(j, i_loop, r); } } if(r) { e_loc = end_loc; flput(j, i_loop, r); } return; } /* ****************************** */ /* ****************************** */ /* ****************************** */ void flput(long k, long l, long m) { /* k=counter l=loop 回数 m=0の時100 0以外は端数あり */ unsigned int i, tbl; i=0; tbl=0; long cnt; tbcl(); while(loc <= e_loc) { fseek(in, loc, SEEK_SET); /* ファイル先頭から */ if(fread(&inch, sizeof(char), 1, in) !=1) { printf("ファイル read error\n"); printf("end_loc=[%ld] e_loc=[%ld] loc=[%ld]\n", end_loc, e_loc, loc); exit(1); } ch = inch >> 4; /* 上位4ビット取り出し */ i = ch; hi[tbl] = chg[i]; ch = inch << 4; /* 下位4ビット取り出し */ ch = ch >>4; i = ch; lw[tbl] = chg[i]; tbl++; loc++; } /* printf("k=[%ld] l=[%ld] m=[%ld] \n", k, l, m); */ fputs(hi, out); fprintf(out, "\n"); fputs(lw, out); fprintf(out, "\n"); fputs(idx, out); cnt = loc % 500; if((!cnt) || (k < l) || ((k) && ((k = l) && (m)))) { fprintf(out, "\n"); } if(!cnt) { fprintf(out, "[%ld] byte\n", loc); } return; } /* ******************************** */ /* File Close */ /* ******************************** */ void fcl(void) { char dum; fclose(in); fclose(out); printf("\n"); printf("******************************************\n"); printf("処理は正常に終了しました。( ̄▽ ̄)ノ ピッ\n"); printf("******************************************\n\n"); scanf("%c", &dum); return; } /* ******************************** */ /* 開始位置入力 */ /* ******************************** */ int st_pos_chk(void) { printf("開始位置を入力して下さい。\n"); printf("開始位置は 100 の整数倍 +1 として下さい。\n"); scanf("%ld", &s_loc); amari = s_loc % 100; if(amari = 1) { s_loc = s_loc - 1; } else { printf("開始位置の入力間違いです。\n"); return 1; } if(s_loc >= end_loc) { printf("開始位置が、ファイルサイズを超えています。\n"); return 1; } return 0; } /* ******************************** */ /* 終了位置入力 */ /* ******************************** */ int ed_pos_chk(void) { printf("終了位置を入力して下さい。\n"); printf("終了位置は 100 の整数倍 として下さい。\n"); scanf("%ld", &e_loc); amari = e_loc % 100; if(e_loc > (end_loc + 1)) { printf("終了位置が、ファイルサイズを超えています。\n"); return 1; } if(!amari) { e_loc = e_loc - 1; return 0; } else { printf("終了位置の入力間違いです。\n"); return 1; } }おまけ(其のニ)・アセンブラ(PC版)
こちらも C言語と同様に興味本位で少しばかり独学してみました。C言語は、解説書を購入して勉強してみたのですが、こちらは、ネット上の資料だけを利用しました。同じ「アセンブリ言語」といっても、大型汎用機のものとはかなり違いがあり、使い勝手というのか・・・かなり戸惑いました(笑)。大型汎用機の方は、命令体系がきちんと整理されていて使い勝手が良いように感じます。また、汎用レジスタの本数や、その種別などもPCの方は何か不満がありました。しかし、かなり前に、「富士通 FM-77」を自宅で「おもちゃ」として使っていたのですが、BASIC言語で作っていたソフトの一部で処理速度が極端に遅いところを、「マシン語」で書き換えたことを考えると、かなり楽でした。というのも、富士通 FM-77用のアセンブラを購入するのが勿体ないので、ハンドアセンブルしていたからです。ハンドアセンブルとは・・・メモリに直接、16進数コードを入力してプログラムを作成するものです。
さて! 話がそれてしまいましので元に戻します。ネットで「MASM」をダウンロードして、ファイル削除のプログラムをプログラムをプログラムを作ってみました。コマンドプロンプトで、削除したい対象ファイルの絶対パスを指定して、そのファイルの内容を NULL クリアした後に、ファイル削除をしています(理由は、わかりますね?)。CODE SEGMENT ASSUME DS:CODE,CS:CODE,ES:CODE,SS:CODE .486 ; .model flat ORG 100h START: call DISP1 ; mov ah,01 ; 処理入力 int 21h cmp al,'9' ; 終了? je OUT1 cmp al,'1' ; ファイル削除? je FLDL cmp al,'2' ; クリアーのみ? jne ERR1 call CLEAR jmp START ERR1: mov ah,9 mov dx,offset EMSG1 ; エラーMSG1を表示する int 21h ; jmp START FLDL: call FILEDEL jmp START OUT1: mov ah,9 mov dx,offset FMSG1 ; 終了メッセージを表示する int 21h ; mov ah,9 mov dx,offset FMSG2 ; 終了メッセージを表示する int 21h ; mov ah,9 mov dx,offset FMSG3 ; 終了メッセージを表示する int 21h ; mov ah,9 mov dx,offset FMSG4 ; 終了メッセージを表示する int 21h ; mov ah,9 mov dx,offset FMSG5 ; 終了メッセージを表示する int 21h ; mov ah,9 mov dx,offset FMSG6 ; 終了メッセージを表示する int 21h ; mov ax,4c00h ; DOS return int 21h ; ****************************************************** ; * タイトル & 処理プロンプト 表示 * ; ****************************************************** DISP1: mov ah,9 ; mov dx,offset MSG01 ; MSG1を表示する int 21h ; mov ah,9 ; mov dx,offset MSG02 ; MSG2を表示する int 21h ; mov ah,9 ; mov dx,offset MSG03 ; MSG3を表示する int 21h ; ret ; ****************************************************** ; * CR&LF 処理 * ; ****************************************************** CR_LF: mov ah,9 mov dx,offset CRLF ; 改行 int 21h ret ; ****************************************************** ; * ファイル削除処理 * ; ****************************************************** FILEDEL: call INPATH mov ah,41h ; ファイル削除 mov dx,offset PATHMOD int 21h ; jnc FILDEL_OK call FILNM_EDT ; *----- ファイル削除不可能メッセージ表示 -----* mov ah,9 ; mov dx,offset MSG09 ; MSG09を表示する int 21h ; mov ah,9 ; mov dx,offset PATHMOD ; FILE名を表示する int 21h ; mov ah,9 ; mov dx,offset MSG10 ; MSG10を表示する int 21h ; mov ah,9 ; mov dx,offset MSG11 ; MSG11を表示する int 21h ; jmp FILDEL_EXT FILDEL_OK: call FILNM_EDT mov ah,9 ; mov dx,offset MSG05 ; MSG05を表示する int 21h ; mov ah,9 ; mov dx,offset PATHMOD ; FILE名を表示する int 21h ; mov ah,9 ; mov dx,offset MSG06 ; MSG06を表示する int 21h ; mov ah,9 ; mov dx,offset MSG07 ; MSG07を表示する int 21h ; FILDEL_EXT: ret ; ****************************************************** ; * ファイルクリアー処理 * ; ****************************************************** CLEAR: call INPATH call FILNM_EDT mov ah,9 ; mov dx,offset MSG05 ; MSG05を表示する int 21h ; mov ah,9 ; mov dx,offset PATHMOD ; FILE名を表示する int 21h ; mov ah,9 ; mov dx,offset MSG06 ; MSG06を表示する int 21h ; mov ah,9 ; mov dx,offset MSG08 ; MSG08を表示する int 21h ; ret ; ****************************************************** ; * ファイル Path 入力 * ; ****************************************************** INPATH: mov ah,9 ; mov dx,offset MSG04 ; MSG4を表示する int 21h ; ; * DS:データの読み書きをするアドレスのセグメントを指します。* ; * DX:汎用レジスター に入力バッファーのアドレスを設定 * ; *********** 以下は、入力バッファーの説明 ********** ; * 0byte 目:入力最大文字数(CR)を含める(プログラマが設定) * ; * 1byte 目:入力された文字数(CR)を含めない(MS-DOSが設定) * ; * 2byte 目以降:入力された文字列 * mov ah,0Ah mov dx,offset PATHIN int 21h ; PATH 入力 mov bx,dx ; call CR_LF ; mov si,bx inc si mov ch,0 mov cl,[si] ;CX ← 入力文字数 inc si ;SI ← 入力文字格納アドレス(lodsbで使用) mov di,offset PATHMOD ;DI ← 入力文字格納アドレス(stosbで使用) PSET: lodsb stosb loop PSET mov al,00h ; ファイル PATH 編集 stosb mov ah,3Dh ; ファイル オープン mov al,2 ; Read & Write mov dx,offset PATHMOD int 21h jnc FILE_SIZE ; Open File Successfully cmp ax,0002h je FERR1 ; File not Exist cmp ax,0003h ; Path not correct je FERR2 mov ah,9 mov dx,offset EMSG2 ; アクセス不能 メッセージ表示 int 21h jmp INPATH FERR1: mov ah,9 mov dx,offset EMSG3 ; ファイルが存在しない メッセージ表示 int 21h jmp INPATH FERR2: mov ah,9 mov dx,offset EMSG4 ; PATH 指定の誤り メッセージ表示 int 21h jmp INPATH FILE_SIZE: mov bx,ax ; ファイルハンドル FILE_SIZE1: mov ax,4202h xor cx,cx xor dx,dx ;ファイルポインタを int 21h ;ファイルの最後部に移動する xchg ax,dx ;↓DX:AXをEAXに変換する shl eax,16 mov ax,dx ;↑ここまで mov ecx,eax ; Loop Counter セット push ecx mov ax,4200h xor cx,cx xor dx,dx ;ファイルポインタを int 21h ;ファイルの先頭に移動する pop ecx ; File Length call CLR_1K ; 1K Byte ずつ Null クリアー REWT: push ecx mov ah,40h mov cx,1 mov dx,offset WR_DATA ; 1 Byte ずつ Null クリアー int 21h pop ecx dec ecx jnz REWT EOF: mov ah,3Eh int 21h ;ファイルクローズ ret ; ****************************************************** ; * ファイル PATH 出力用編集 * ; ****************************************************** FILNM_EDT: mov dx,offset PATHIN mov si,dx inc si mov ch,0 mov cl,[si] ;CX ← 入力文字数 inc si ;SI ← 入力文字格納アドレス(lodsbで使用) mov di,offset PATHMOD ;DI ← 入力文字格納アドレス(stosbで使用) NSET: lodsb stosb loop NSET mov al,24h ; ファイル PATH 編集 stosb ret ; ****************************************************** ; * 1 K Byte ずつファイルをクリア-する 2009.01.30 追加* ; ****************************************************** CLR_1K: xor edx,edx mov eax,ecx div CR_LEN cmp eax,0 jz CLR_1K_EXT ; ファイルが 1 K Byte 未満 mov ecx,eax ; Loop カウンターをセット CLR_1K_1: push ecx mov ah,40h mov cx,1024 mov dx,offset CR_DATA ; 1024 Byte ずつ Null クリアー int 21h pop ecx dec ecx jnz CLR_1K_1 CLR_1K_EXT: mov ecx,edx ; 1024 以下のバイト数をLoopカウンターにセット ret ; *----------------------------------------------------* ; * DATA AREA * ; *----------------------------------------------------* MSG01 DB 0Dh,0Ah,'FILE 削除ツール(開発言語:アセンブラ)',0Dh,0Ah,24h MSG02 DB '1:ファイル削除 2:ファイルクリアのみ 9:処理終了',0Dh,0Ah,24h MSG03 DB '処理を選択して下さい',24h MSG04 DB 0Dh,0Ah,'対象のファイル名称をフルPATH で指定して下さい。',0Dh,0Ah,24h MSG05 DB 0Dh,0Ah,'☆☆☆ ',24h MSG06 DB ' ☆☆☆は正常に',24h MSG07 DB '削除されました。',0Dh,0Ah,24h MSG08 DB 'クリアーされました。',0Dh,0Ah,24h MSG09 DB 0Dh,0Ah,'◎◎◎ ',24h MSG10 DB ' ◎◎◎は',24h MSG11 DB '削除できませんでした。',0Dh,0Ah,24h ; FMSG1 DB 0Dh,0Ah,0Dh,0Ah,'☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆',0Dh,0Ah,24h FMSG2 DB '☆ プログラムは正常に終了しました ☆ ( ̄▽ ̄)ノ ピッ ☆',0Dh,0Ah,24h FMSG3 DB '☆☆☆☆☆☆☆ 製作著作: ☆☆☆☆☆☆☆',0Dh,0Ah,24h FMSG4 DB '☆☆☆☆☆☆☆ Ver. 1.0 2009.01.20 ☆☆☆☆☆☆☆',0Dh,0Ah,24h FMSG5 DB '☆☆☆☆☆☆☆ Ver. 1.1 2009.01.30 ☆☆☆☆☆☆☆',0Dh,0Ah,24h FMSG6 DB '☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆',0Dh,0Ah,24h ; EMSG1 DB 0Dh,0Ah,0Dh,0Ah,'処理は 1か2、または9で指定してください。',0Dh,0Ah,0Dh,0Ah,24h EMSG2 DB 0Dh,0Ah,0Dh,0Ah,'ファイルにアクセスできません。',0Dh,0Ah,0Dh,0Ah,24h EMSG3 DB 0Dh,0Ah,0Dh,0Ah,'指定されたファイルが存在しません。',0Dh,0Ah,0Dh,0Ah,24h EMSG4 DB 0Dh,0Ah,0Dh,0Ah,'PATH の指定が正しくありません。',0Dh,0Ah,0Dh,0Ah,24h ; CR_LEN DD 1024 ; CRLF DB 0dh,0ah,24h PATHIN DB 81,0,81 dup(?),?,?,? ; 入力バッファー PATHMOD DB 100 DUP(?) ; 編集された file Path CR_DATA DB 1024 DUP(0) WR_DATA DB 0 ; *----------------------------------------------------* CODE ENDS END START